A Case Against A/B Testing

Swiss Army Knife Love Affair
A/B tests will fail you; when they do, make sure the sky does not come crashing down on your head. This post was inspired by a talk given by Nelson Ray from OpenDoor at Data Day Texas - 2017. [1]
A/B Tests have become muscle memory for many in the tech & software world. The answer to any hard question often seems to be: Let's run an A/B test!. While this is an extremely powerful practice [2], it does have limitations.
Without getting into A/B tests only finding local maxima[3], and not even addressing the false conclusions accompanying shortened tests [4] (BEWARE: classical statistics are lurking ahead in that read)- there are still other reasons to look at little closer at the reigning champion of data-driven cultures.
It turns out that our beloved AB tests do infect have some sharp edges.
How does your organization handle cases where:
- Can you not afford the “B” test of an AB Test?
- Your users can’t afford the “B” test version. (Perhaps users only complete the Call-To-Action every so often within the A/B Test?)
- Don’t you have enough users to sufficiently A/B test?
- Your action/observation does not take place but every 7 years on average?
"Show me an AB test that ran to completion but was still non-conclusive, and I'll show you the average A/B Test." - Nelson Ray [1]
Funnel of Confidence
In his Data Day talk, Ray presented a thought I had never considered. It was called the “Funnel of Confidence”.
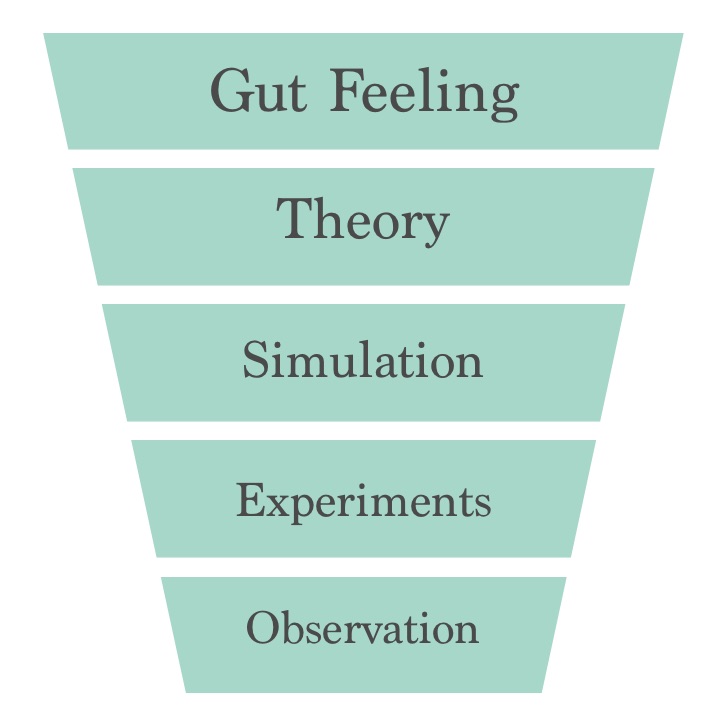
The farther down you reach into the funnel, the more it costs, and often the longer it will take to come up with a contextually rich conclusion. Additionally, the probability of arriving at a contextually rich conclusion is the greatest (absolutely certain) at the bottom the funnel. The top is “free” in terms of time and effort and the bottom ranges from “costly” to “as much as you want to spend.”
All too often, the software industry forgets there are other tools in the shed. The AB test is great but, a silver bullet it is not. Consider the OpenDoor business of buying and selling houses via their website. Their pricing algorithm is arguably their whole product; sure, there are other auxiliary services that make their algorithm useful. The core of their operation really centers around their home pricing algorithm and the surrounding human psychology.
Any given house changes owners every 7 years, on average. Thus running pricing model A/B Tests can be slow, costly, and fraught with the problems mentioned before. So Rya and opendoor.com explored using other houses (or “comps”) to test their pricing models. However, this introduces its own type of bias and non-conclusive guarantees, and since the only “true experiments” would watch one house at a time. But again, to watch each test complete on a single house, you need to pack more than a lunch while you wait for the spinner to finish about 7 years later.
There has to be a better way - especially with this idea of “comps”, or similar houses.
A case for Simulations
With this home pricing algorithm as a motivating example, we give up (or at least we should) on A/B Tests real quick. Enter the simulation. With enough historical data, you can simulate your algorithm on those historical data and see how you would have done under each algorithm strategy, or model. Many people know this as back-testing, a highly touted feature of a trading desks like TD Ameritrade, or Scottrade, etc.
In the OpenDoor case, there tends to be plenty of public pricing data to run algorithms over and observing generated outcomes for the company. When data does not exist, often you can create or simulate your users too which creates a Monte Carlo simulation. At some point, your board will hears that some of the analysis your company is going to hang its hat on is being generated via your own internal models, and know it will generate panic. Depending on the stage of the company, and its competencies, the panic maybe warranted. However, for many early stage companies, this is an extremely pragmatic way to evaluate your algorithm. It is also useful to recall the best fact about models.
"All models are wrong, but some models are useful." - George Box [5]
So as you venture off to create your models and simulations, be sure to always keep your eye on the useful models.[6]
Conclusion
When you hit a rough patch with your constant A/B Tests make sure:
- You have a problem suited for AB Testing
- Let your experiments complete before short changing them.
- You have visibility to the number of AB Tests running concurrently[7]
If you find that your situation is not conducive for AB Tests:
- Stop trying to fit the square peg in the round hole.
- Consider if a simulation might be a better approach to making a data-informed decision.
"All experiments say something, but some say it more loudly than others." - Eric D Moore [8]
Reference & Citations:
Article: from 52WeeksofUX.com ↩ ↩
Commentary: on [2] from KissMetrics ↩
George Box on Wikipedia: ↩
Credit: a circular quote reference to engender credibility from the reader ↩